Why Do Data Visualization Mistakes Matter?
Although data visualization has been in place since 1780, when the first bar chart was produced by a toy company in Scotland, the practice is still imperfect. Both intentional, misleading data visualization “mistakes” as well as honest mistakes made during output are more common in the business world than one might think.
Intentional “Errors”
When an organization wants to get a point across without providing much evidence, “statistical manipulation” is commonplace. Though a dishonest practice, it’s still widely seen in business today. Typically, organizations will leave out the scale on a bar graph or pie chart. Then, they will intentionally emphasize disparities or relationships in the data, with no actual scale to which viewers can compare each bar.
Virtually any data set can be made to look off-target using this method. While experienced analysts would be able to question or see right past this type of reporting, individuals unfamiliar with the data may not. As a side effect, this manipulation and bias could lead to a loss of credibility or potential revenue.
Unintentional Errors
The “weakest link” in the chain of statistical reporting is often the human generating the report. Even if there’s no reason for the person making the report to be misleading, their reports could unintentionally appear this way. Most often due to a lack of experience or context on the matter, these mistakes look deceiving and can result in a loss of integrity.
Who is Responsible for These Mistakes?
Most organizations have several layers of employees. While a report may be generated by an individual analyst, the responsibility for its contents is typically on the department that ends up releasing it.
It can be hard to take a step back and think objectively when you’re the one working so closely with the data. This is why it’s critical to get multiple perspectives on the veracity of your reports before releasing them. Alternatively, you may choose to train an internal department that reviews every data set before it’s released to the public or another company.
What Are the Five Most Common Mistakes?
While there is an abundance of potential mistakes that could occur during the creation of a data set, some are more common than others. Here are the five issues we see the most often when it comes to data visualizations. They are important to avoid as all of these can be harmful to a company’s reputation and credibility overall.
1. Unlabeled X-Axis Start
A common technique in intentional data distortion, this is an abuse of the common conclusion that readers would draw from your chart. Unless otherwise marked, readers assume that your X-axes start at 0. Starting them at a higher number to emphasize smaller disparities is beyond merely “tweaking” a chart.
2. An Inverted Y-Axis
Elementary school-level math taught most of us that our X-axis and Y-axis should start at zero and go up from there. If an analyst wants to convey a message that’s the opposite of the results, flipping an axis is a great way to do that. However, this method rarely pays off due to the irregular visualization. Experienced viewers will undoubtedly detect this.
3. Scale Truncation
We all expect bar charts to be linear in nature. However, if someone generating the chart wants a number to appear lower than it actually is, truncating it is the way to go. This is when you might see a small squiggle in a bar chart that randomly cuts out a large number. Ostensibly, the reason is usually to “keep it all on one page.” However, simply changing the scale rather than truncating arbitrary columns is how to keep it honest.
4. Cherry-Picking Scales
This is when a chart has data in arbitrary units. These are typically (but not always) intentionally engineered to make two scales either as close to each other as possible or as far away from each other as possible. It’s important to use the same units wherever possible. If it’s not possible, this must be clearly distinguished.
5. Including Too Much Data
Not always done intentionally but confusing nonetheless, this is when a chart has far too much data for the average reader to interpret. Charts should be kept as simple as possible. This will allow viewers to quickly and easily understand the information presented.



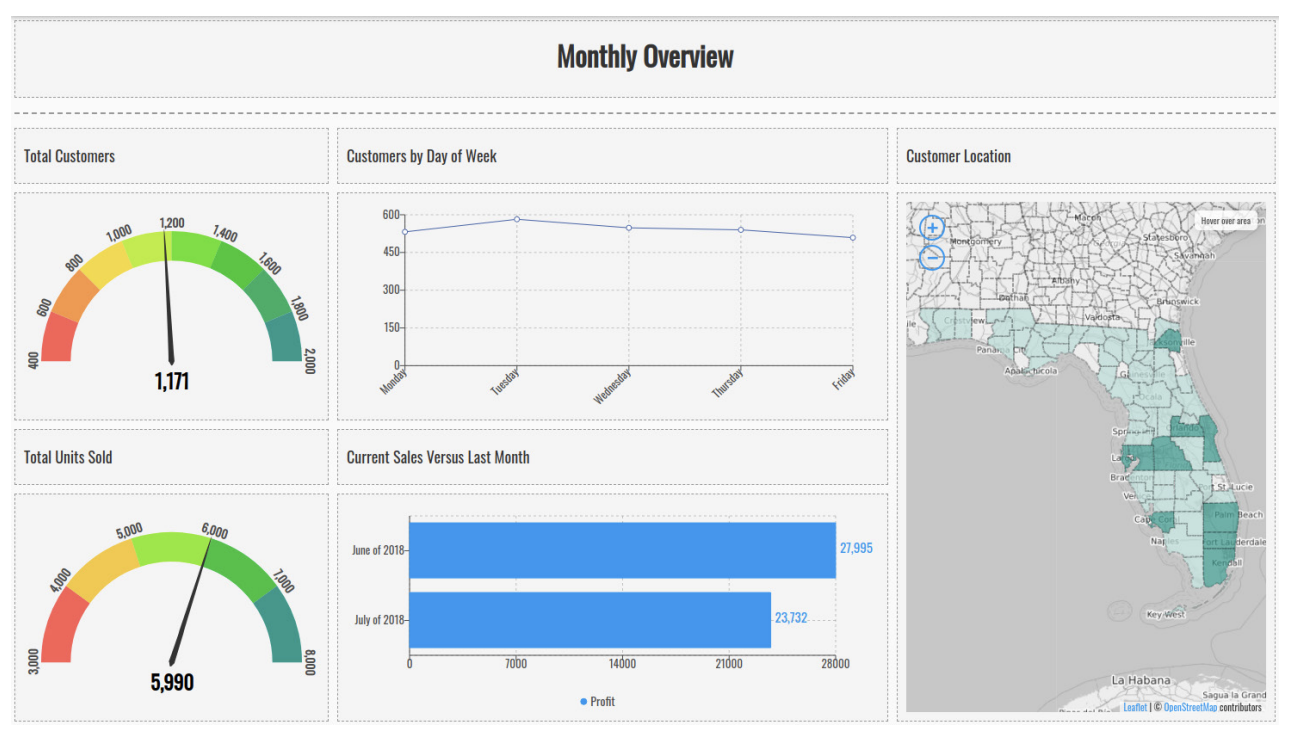
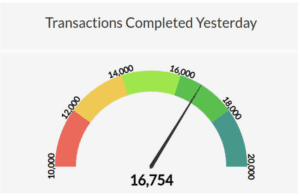 A gauge is an exceptionally clear visual. It shows exactly where a number falls between a minimum value and maximum value. If you want to show how your sales performance was for a specific time period, a gauge will allow a user to instantly know if you did better or worse than expected.
A gauge is an exceptionally clear visual. It shows exactly where a number falls between a minimum value and maximum value. If you want to show how your sales performance was for a specific time period, a gauge will allow a user to instantly know if you did better or worse than expected.