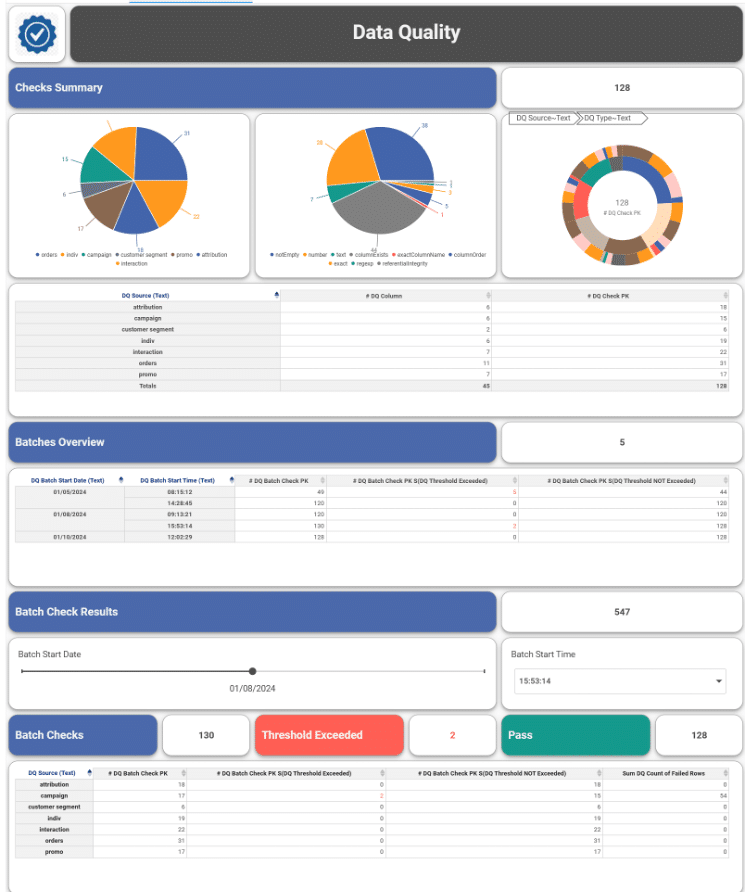
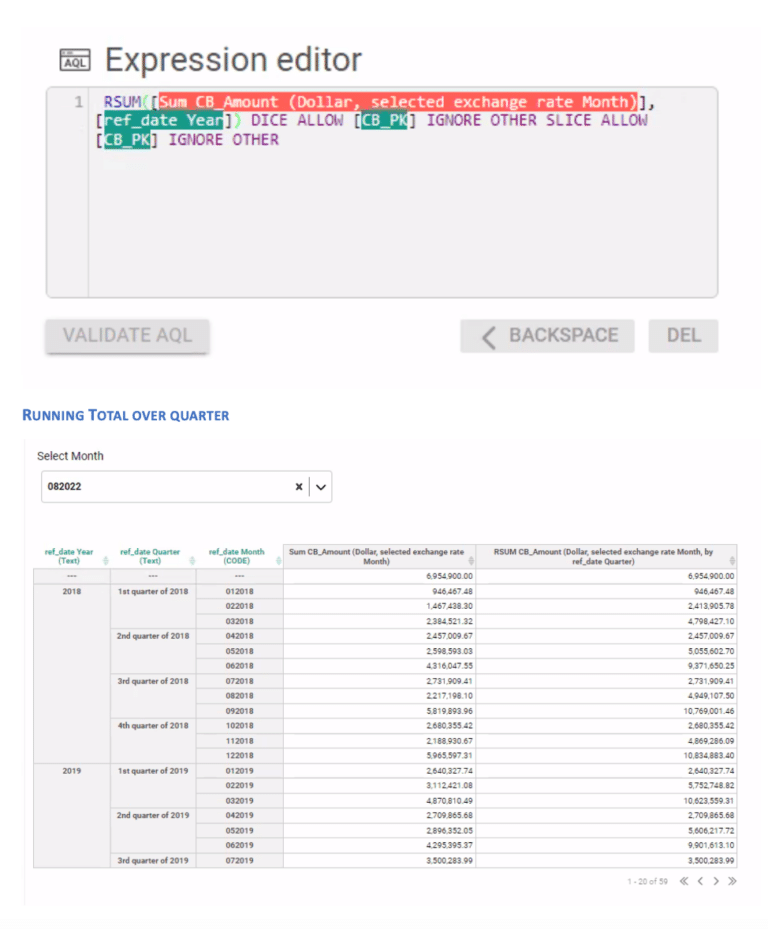
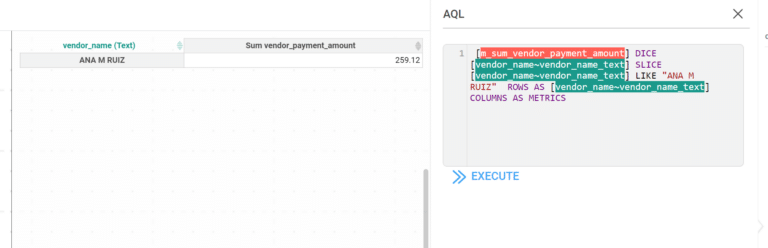
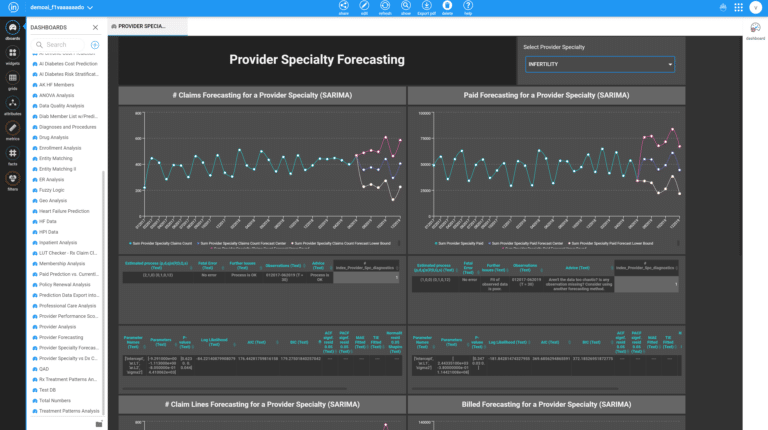
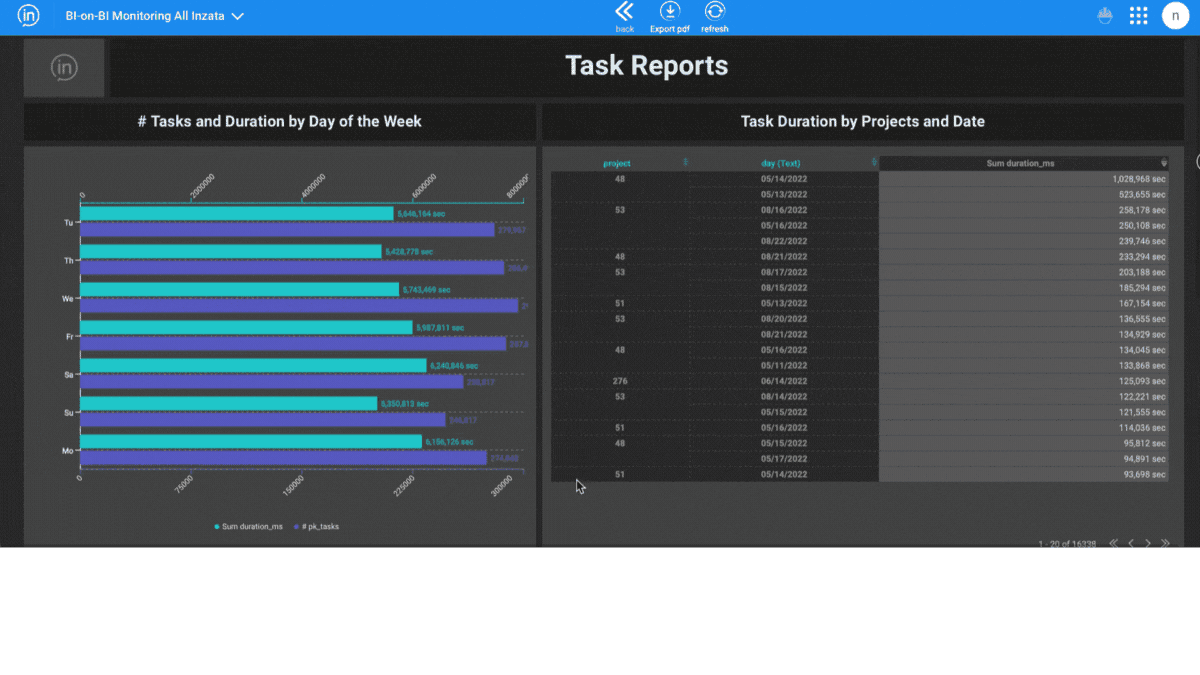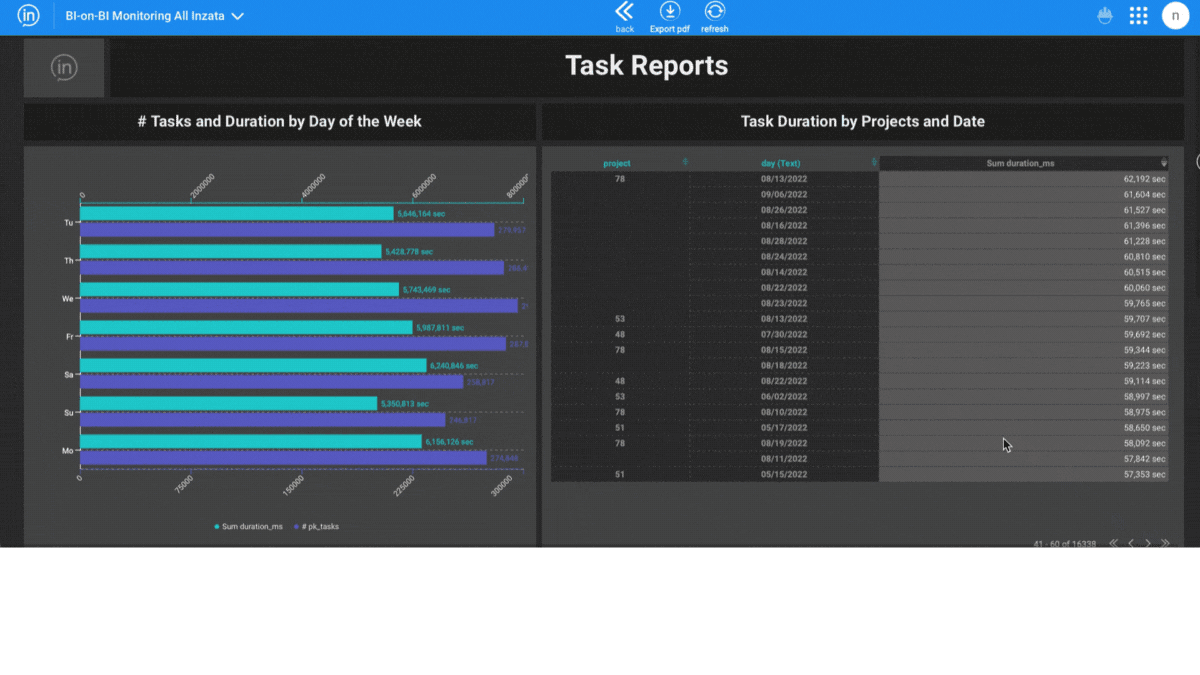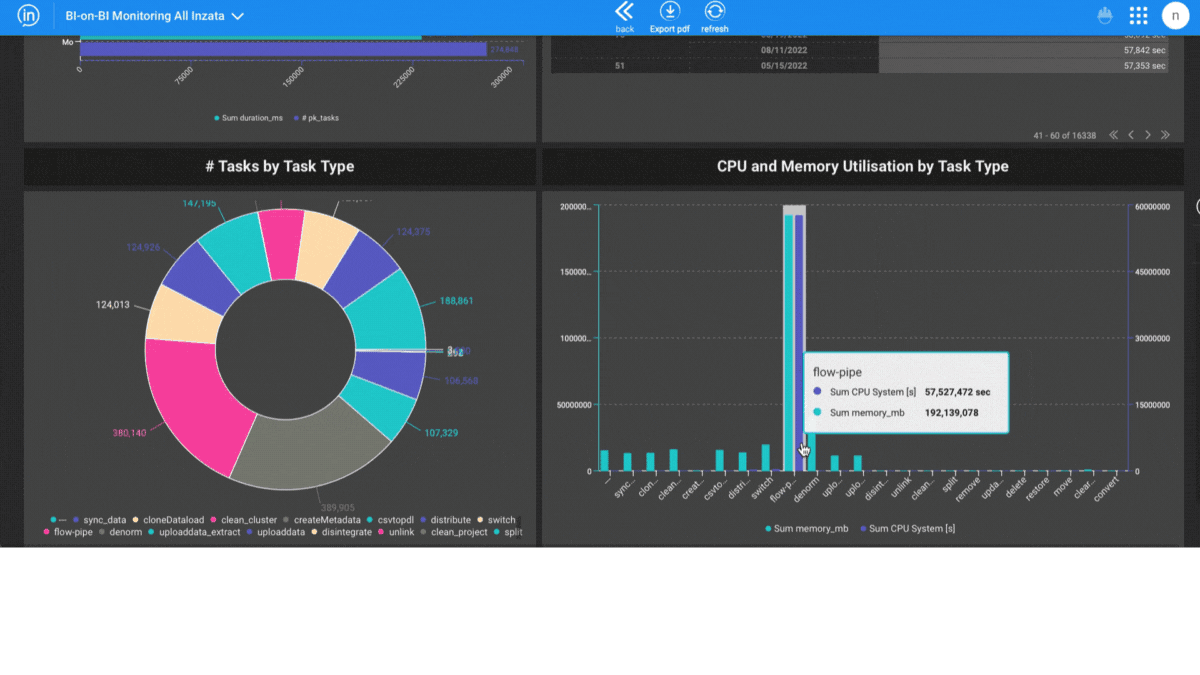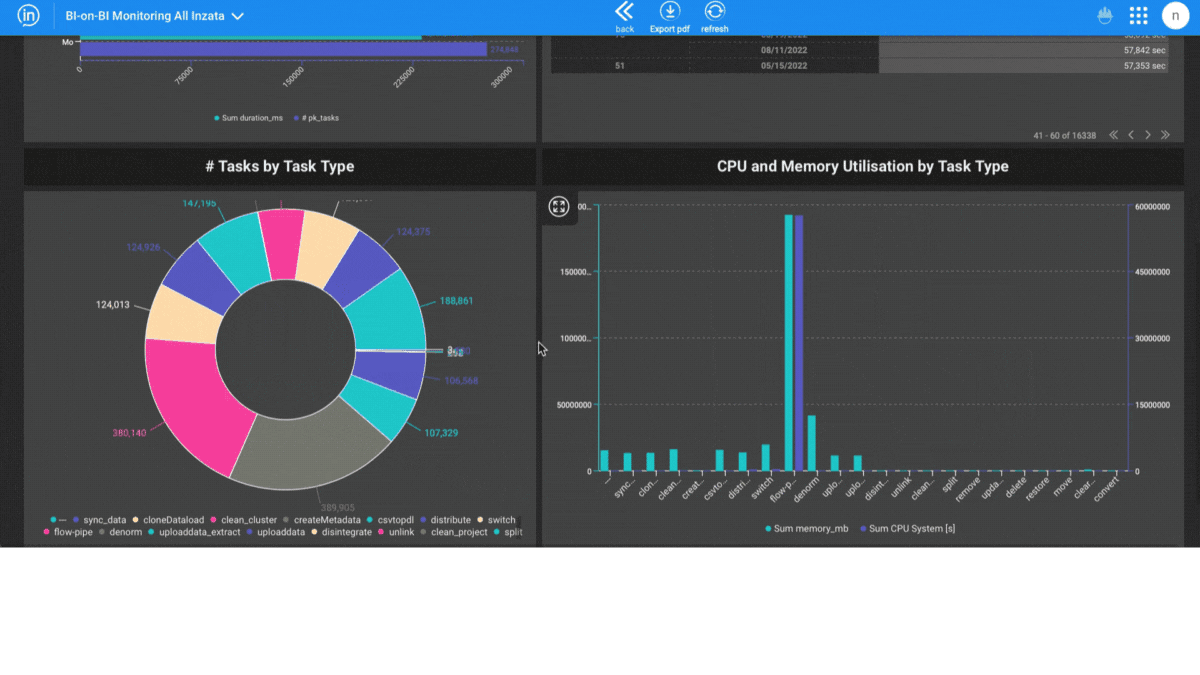
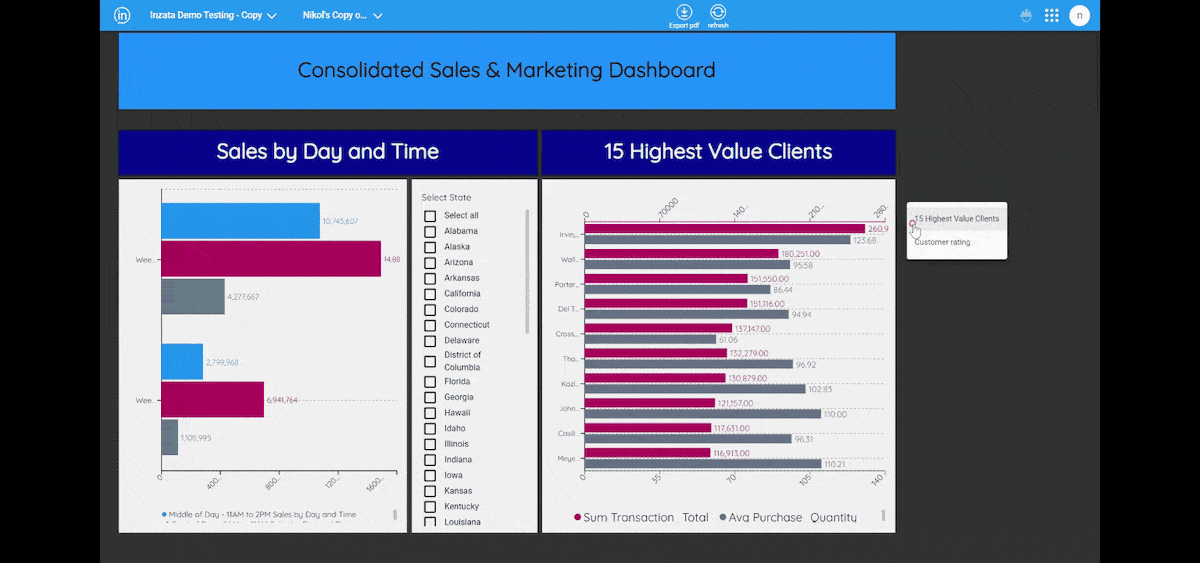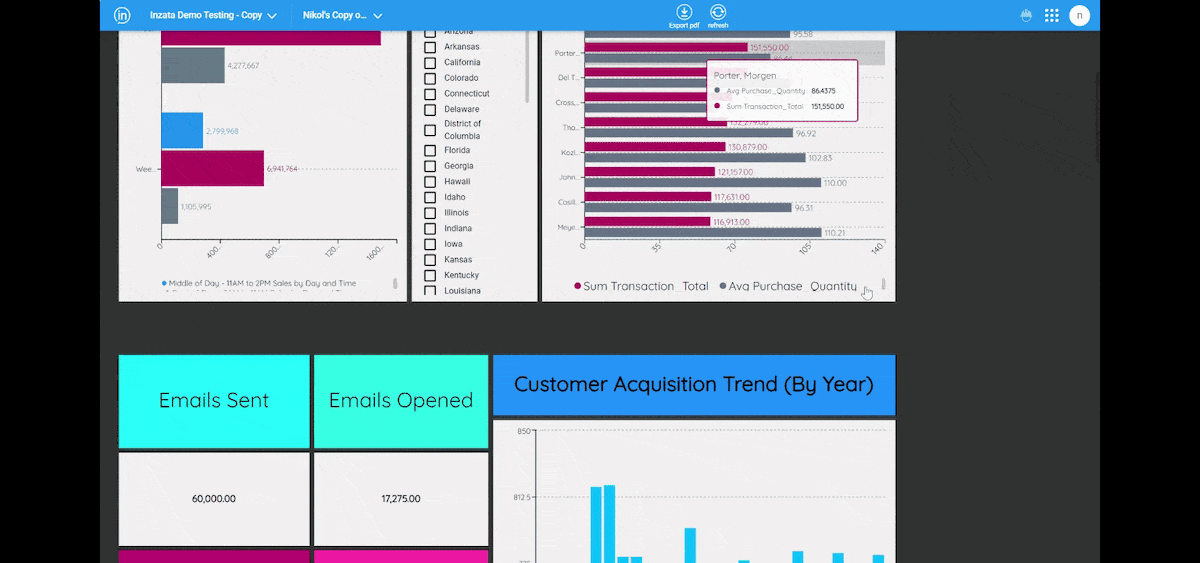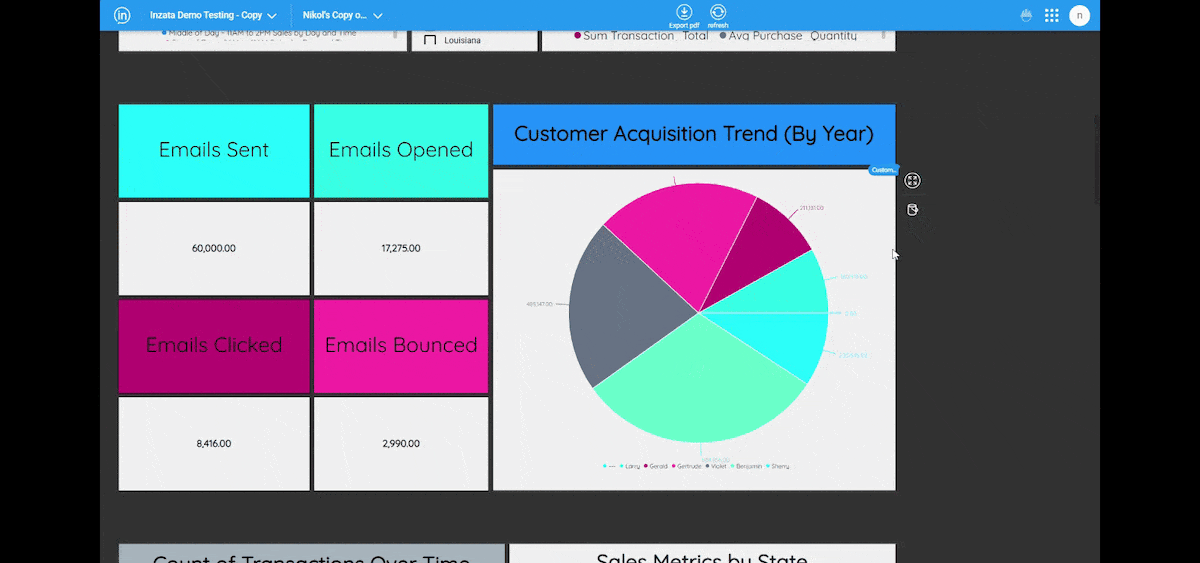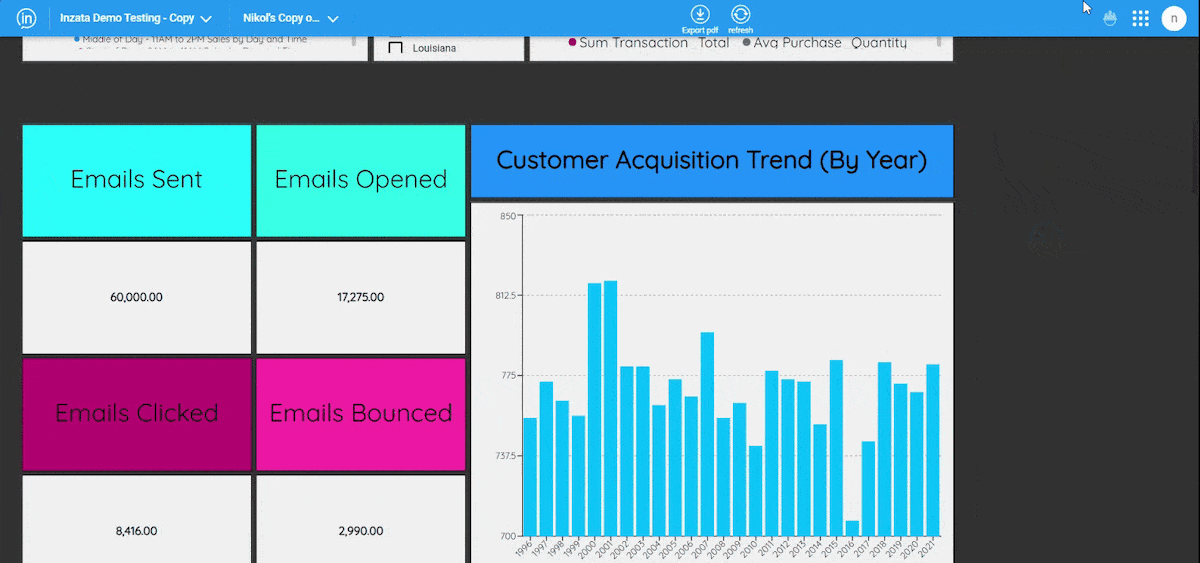
Entities Matching is a crucial component in the process of data integration, and it is supported by Inzata’s advanced AI/ML library. The library is designed to handle deduplication and record linkage at scale, using an unsupervised learning approach. This approach allows for the identification of similar records, even when there is no explicit identifier that links them together.
Addressing Challenges in Entity Matching and Data Quality
One of the common scenarios where entity matching is required is when multiple distinct records relate to the same entity, but there is no way to connect them. For example, customers may have made orders under different accounts or without registration, and the data may come from multiple sources. This can lead to a large number of duplicate records, which can negatively impact the quality of the data and the accuracy of any analysis or reporting that is based on it.
Typographical errors are another major issue that can affect data quality, especially when it comes to identifying entities. These errors can occur when data is entered manually, and they can make it difficult to match records that should be linked together. Additionally, changes in entities’ identification information can also make it challenging to match records.
Inzata’s AI/ML library addresses these challenges by using advanced algorithms to detect and integrate the same entities before further data processing. This allows organizations to improve the accuracy and completeness of their data, resulting in more accurate and reliable insights and decision-making.